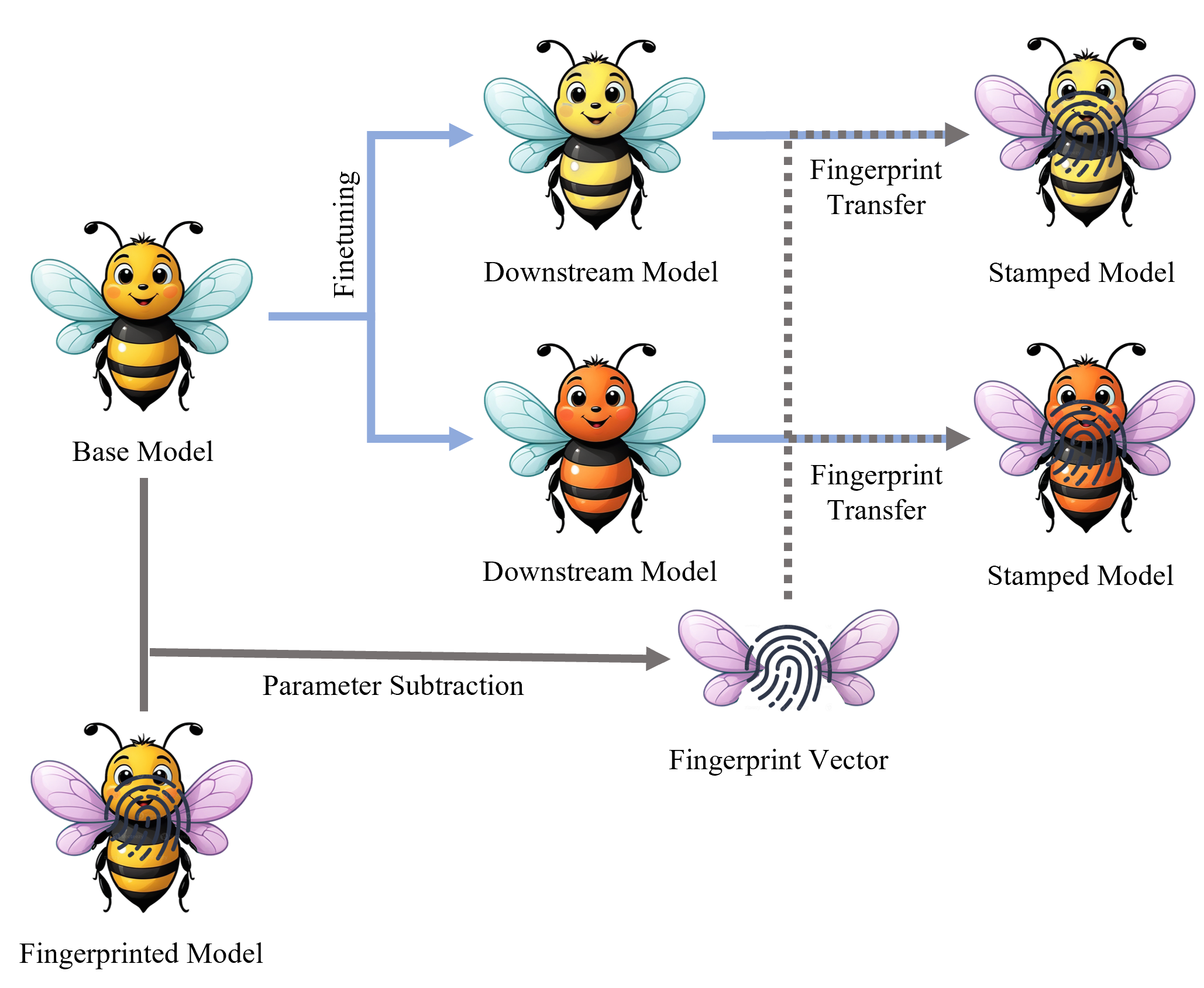
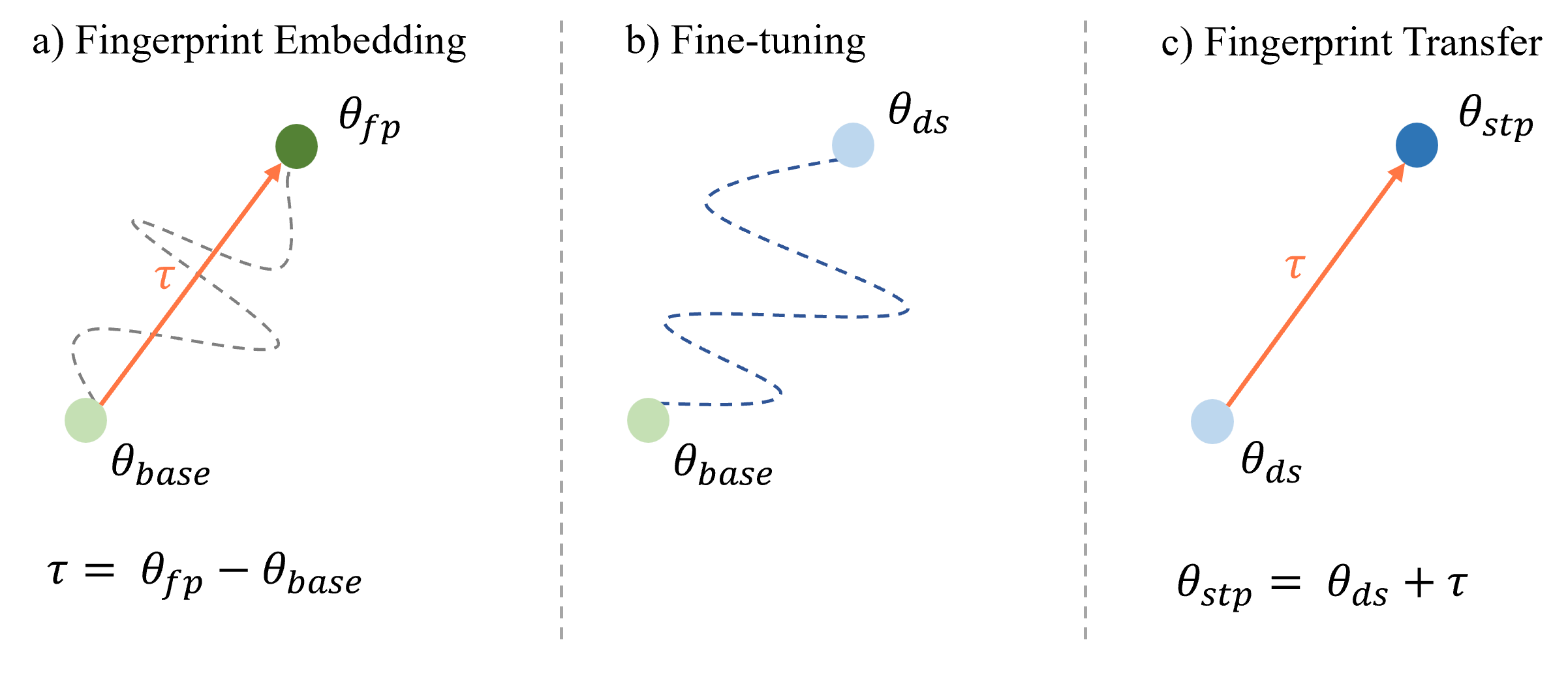
Fig. 1: An illustration to FP-VEC. The blue arrows on the top left illustrate the process of obtaining downstream models by fine-tuning the base model on the target task. In contrast, the gray arrow shows how we derive the fingerprint vector through simple parameter subtraction. This fingerprint vector can then be added to the downstream model, producing the stamped model, as indicated by the gray arrow dash lines.